深入探讨日文编码系统与乱码关系解析之核心原理与应对策略
在计算机领域,日文编码系统是一个重要的话题。正确理解和处理日文编码系统对于处理日文文本至关重要,因为不正确的编码可能导致乱码问题。将深入探讨日文编码系统与乱码之间的关系,并解析其核心原理以及应对策略。
让我们了解一下日文编码系统的基本概念。日文编码系统是用于将日文字符转换为二进制数字的规则和标准。常见的日文编码系统包括 Shift_JIS、EUC-JP、UTF-8 等。这些编码系统使用不同的方式来表示日文字符,因此在不同的系统之间可能会出现编码转换的问题。
乱码的产生通常是由于编码不匹配或编码错误导致的。当计算机尝试读取或显示日文文本时,如果使用的编码与实际的编码不匹配,就会出现乱码。例如,如果一个文件使用 Shift_JIS 编码,但在另一个系统中使用 EUC-JP 编码打开,就可能会出现乱码。
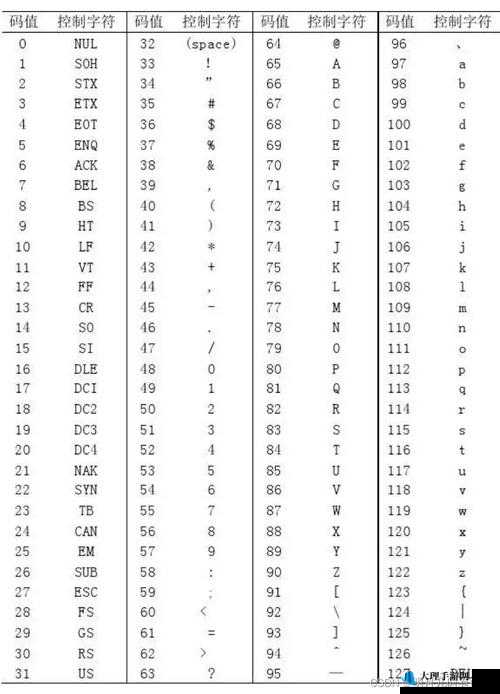
为了解决乱码问题,我们需要了解编码系统的核心原理。编码系统通常使用特定的字符编码表来将字符映射为二进制数字。这些字符编码表定义了每个字符对应的编码值。在日文编码系统中,字符的编码值通常是基于 Unicode 标准的。
为了正确处理日文文本,我们可以采取以下应对策略:
1. 确保使用正确的编码:在处理日文文本时,始终使用与文本实际编码匹配的编码系统。例如,如果文本是 Shift_JIS 编码的,就应该使用 Shift_JIS 编码来读取和显示。
2. 进行编码转换:如果需要在不同的编码系统之间进行转换,可以使用编码转换工具或库来确保转换的准确性。
3. 检查和验证编码:在读取和显示日文文本之前,检查编码是否正确。可以使用在线编码检测器或专门的编码工具来验证编码。
4. 遵循最佳实践:遵循一些最佳实践可以帮助避免乱码问题。例如,将日文文本存储为 UTF-8 编码,以确保在不同的系统中都能正确显示。
正确理解和处理日文编码系统对于避免乱码问题至关重要。通过了解编码系统的核心原理和采取适当的应对策略,我们可以确保日文文本在不同的系统和应用程序中能够正确显示,提供更好的用户体验。